La importancia de trabajar al límite
Última actualización: 21.10.2025
5 minutos
La generación de datos en el perímetro superará en pocos años la capacidad de almacenamiento de todos los centros de datos del mundo. Por eso, la tendencia es procesar los datos directamente en el perímetro con algoritmos inteligentes y aprendizaje automático.
El mercado del IoT está creciendo, y con él, el número de dispositivos conectados dentro de este universo. Los dispositivos abarcan desde sofisticadas máquinas industriales hasta un simple interruptor de la luz en la pared. Cada uno de estos dispositivos puede enviar datos, y los algoritmos pueden aprender de ellos.
IDC calcula que en 2025 tendremos 41.600 millones de dispositivos IoT capaces de enviar datos. Estos dispositivos generarían 79,4 Zettabytes de datos. Para poner esa cifra en perspectiva, todos los centros de datos del mundo pueden almacenar actualmente 6,7 Zettabytes de datos. Por no hablar de que nuestra red de datos debe transferir estas grandes cantidades de datos.
El problema es que la mayoría de estos datos son basura. La mayoría de las veces no ocurre nada digno de mención, así que ¿qué sentido tiene almacenar datos que no sirven para nada? Por eso tiene sentido preprocesar los datos en el extremo -el dispositivo IoT- y enviar sólo los que contengan información valiosa.
Ya lo hicimos en el pasado
Trabajar en el límite no es nada nuevo. Ya lo hicimos durante la misión a la Luna en los inicios de los viajes espaciales. La mayor parte de los datos registrados por los sensores de la nave espacial también se procesaban en ella. Enviarlos de ida y vuelta a la Tierra crearía un retraso considerable, que podría haber puesto en peligro la vida de los astronautas.
Muchos sensores pequeños pueden preprocesar los datos y "despertarse" cuando ocurre algo. Por ejemplo, el BMI150, una IMU (Unidad de Medición Inercial) de Bosch, puede detectar dobles toques o elevarse para despertarse en el chip. No es sofisticado, pero es un procesamiento de datos muy avanzado.
Durante algún tiempo nos alejamos del procesamiento descentralizado de datos e intentamos hacerlo todo en la nube. Con la aparición de los coches autónomos, los smartphones, las fábricas inteligentes y mucho más, los ingenieros y las empresas se dieron cuenta de que cuanto más procesamiento hagan los microcontroladores en el borde, mejor para los costes y más eficiente, ágil y rápido se vuelve el sistema.
Imagina que "Oye, Siri" funcionara solo en la nube. Eso significaría que hay que establecer un flujo constante entre el micrófono y la nube. En cualquier caso, un escenario horrible en lo que respecta a la privacidad, la carga de la red, el procesamiento de datos y mucho más.
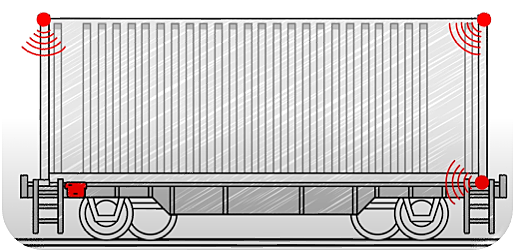
Ejemplo: Hacer inteligentes los trenes de mercancías
Los trenes de mercancías son simples vehículos mecánicos construidos para transportar diversas mercancías de A a B. Los propietarios de estos trenes de mercancías no tienen forma de saber cómo utilizan los clientes sus trenes de mercancías o si chocan con algo en la vía.
Las colisiones y las duras operaciones de carga y descarga dañan los trenes con el tiempo. Esto tiene efectos perversos en su mantenimiento y, con ello, en los costes que generan para la empresa. Responsabilizar a los clientes del mal uso de los trenes de mercancías reduciría mucho los costes de la empresa. En el peor de los casos, estos trenes dañados provocan catástrofes en las que hay seres humanos implicados.
La solución: utilizar un centro de sensores con aprendizaje automático en el borde para que los trenes de mercancías sean más inteligentes.
¿Cómo hacer que los trenes de mercancías sean inteligentes?
Hay tres retos clave a la hora de intentar que estos trenes sean más inteligentes. Estos trenes no están conectados a ninguna red eléctrica, por lo que necesitamos una fuente de alimentación independiente que pueda alimentar el dispositivo durante años. Necesitamos conectarlos a una red para enviar y recibir datos y no enviar demasiada información para mantener los secretos del operador.
El concentrador de sensores
El concentrador de sensores contiene nuestra IMU básica de 9 ejes (unidad de medición inercial: acelerómetro, giroscopio y magnetómetro) junto con el GPS y las capacidades de red. El microcontrolador que se ejecuta en el centro de sensores debe ser capaz de ejecutar modelos sencillos de aprendizaje automático, por ejemplo, modelos generados con Tensorflow Lite.
Entrenar, desplegar y reiterar
Nuestro modelo necesita datos. Para recopilar estos datos, necesitamos grabar unos cuantos trenes de forma consistente, a expensas de cambiar la batería de los que van antes que los de otros trenes. También podemos simular choques, colisiones y entornos de carga difíciles e introducir esos datos en nuestros modelos.
Otro aspecto importante de nuestros modelos es asignar zonas geográficas a los clientes y saber, a partir del número de choques detectados, cuáles de ellas son clientes demasiado bruscos con los trenes. La combinación de los datos del GPS y los sensores es inestimable para aprender cuándo y dónde sufren daños los trenes.
El modelo se entrena continuamente y se despliega en los demás dispositivos, haciéndolos más "inteligentes" con el tiempo.
Despliegue de la plataforma IoT para procesar los datos
El modelo de aprendizaje automático supervisa los datos de los sensores y se asegura de que el microcontrolador sólo envíe datos útiles a la plataforma IoT. En este caso, nuestra plataforma digital IoT A1 recibe las señales GPS de los concentradores de sensores y las presenta en un mapa.
Podemos hacer más clic en estos dispositivos y obtener más información sobre ellos. La información contiene, por ejemplo, una foto del activo, su número de serie o el año de fabricación. Como utilizamos IMU, o sensores de choque, podemos crear alarmas para nuestros activos. Estas alarmas se ejecutan cuando los sensores superan un determinado umbral, o nuestros modelos detectan que algo le ha ocurrido a nuestro activo.
Con este resumen podemos ver dónde y cuándo le ha pasado algo a nuestro tren. En el mejor de los casos, podemos responsabilizar a alguien de los daños sufridos por nuestros trenes.
Ventajas de trabajar al límite
Reducir el consumo de energía del dispositivo
Reducir la velocidad de transmisión de datos: conservar el ancho de banda
Mejorar la privacidad
Reacción en tiempo real a los acontecimientos
Reducción de la latencia
Habilitar aplicaciones inteligentes
El aprendizaje automático en los bordes se produce con mayor frecuencia, y el preprocesamiento de datos en los bordes será una necesidad cuanto más avancemos en el universo de la Internet de las Cosas. Hacer que los trenes de mercancías sean más inteligentes es solo un caso de uso de los muchos en los que el ML en los bordes desempeña un papel importante en la reducción de costes, el aumento de la eficiencia y la automatización del sistema.



