The Importance of Working on the Edge
Category
Solutions
Reading time
Data generation on the edge would outstrip the storage capacity of all data centers around the world in a few short years. So the trend is moving toward processing data directly on the edge with intelligent algorithms and machine learning.
The IoT market is growing, and with it, the number of connected devices within this universe. Devices reach from sophisticated industrial machines to a simple light switch on the wall. Each ofthese devices can send data, and algorithms can learn from them.
IDC estimates that by 2025 we’ll have 41.6 billion IoT devices capable of sending data. These devices would generate 79.4 Zettabytes of data. To put that number into perspective, all data centers in the world can currently store 6.7 Zettabytes of data. Not to mention that our data network must transfer these large amounts of data.
The problem is that most of this data is garbage. Most of the time, nothing mention-worthy happens, so what’s the purpose of storing data that serves no purpose? That’s why it makes sense to pre-process the data on the edge - the IoT device - and send only data that contain valuable information.
We've done it in the past
Working on the edge is nothing new. We’ve done it during the moon mission in the early innings of space travel. Most of the data recorded by the sensors on the spaceship were also processed on the spacecraft. Sending it back and forth to earth would create a considerable delay, which could’ve been life-threatening for the astronauts.
Many small sensors can pre-process data and “wake up” when something happens. For example, the BMI150, an IMU (Inertial Measurement Unit) by Bosch, can detect double-taps or rise for wake up on-chip. It’s not sophisticated, but it is data processing on the very edge.
We moved away from decentralized data processing and tried to do everything in the cloud for some time. With the emergence of autonomous cars, smartphones, smart factories, and much more, engineers and companies realized that the more processing the microcontrollers do on the edge, the better for the costs and the more efficient, leaner, and faster the system becomes.
Imagine if “Hey, Siri” works only in the cloud. That’d mean that a constant stream must be established between the microphone and the cloud. Under all circumstances, a horrific scenario concerning privacy, network load, data processing, and much more.
Example: Making freight trains smart
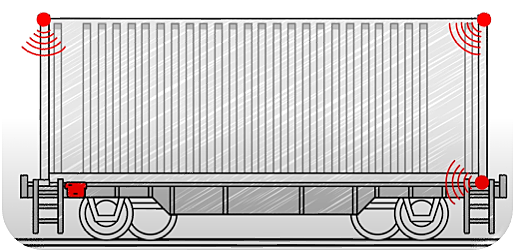
Freight trains are simple mechanical vehicles built to transport various goods from A to B. The owners of these freight trains have no way of knowing how customers use their freight trains or if they collide with something on the track.
Collisions and rough loading and unloading damage the trains over time. These have perverse effects on their maintenance and, with it, the costs they generate for the company. Holding customers accountable for misusing freight trains would reduce the company’s costs by a lot. In the worst case, these damaged trains lead to disasters where humans are involved.
The solution - use a sensor hub with machine learning on the edge to make freight trains smarter.
How to make freight trains smart?
There are three key challenges when trying to make these trains smarter. These trains are not connected to any power grid, so we need an independent power supply that can power the device for years. We need to connect them to a network to send and receive data and not send too much information to keep the secrets of the operator.
The sensor hub
The sensor hub contains our basic 9-axis IMU (Inertial Measurement Unit - Accelerometer, Gyroscope, Magnetometer) together with GPS and network capabilities. The microcontroller running on the sensor hub must be able to run simple machine learning models - for example, models generated with Tensorflow Lite.
Train, deploy and reiterate
Our model needs data. To gather this data, we need to record a few trains consistently at the expense of exchanging the battery of those earlier than those on other trains. We can also simulate shocks, collisions, and rough loading environments and feed that data into our models.
Another important aspect of our models is to assign geographic zones to the customers and learn from the number of detected shocks which one of these are customers is too rough with the trains. Combining the GPS data and the sensors is invaluable to learning when and where the trains take damage.
The model is continuously trained and deployed to the other devices, making them more “intelligent” over time.
Deploy the IoT platform to process the data
The machine learning model monitors the data from the sensors and ensures that the microcontroller only sends useful data to the IoT platform. In this case, our A1 digital IoT platform receives the GPS signals of the sensor hubs and presents them on a map.
We can click further into these devices and get more information about them. The information there contains, for example, a picture of the asset, its serial number, or manufacturing year. Because we’re using IMUs - or shock sensors - we can create alarms for our assets. These alarms execute when the sensors exceed a certain threshold, or our models detect that something happened to our asset.
We can see where and when something happened to our train with this overview. In the best case, we can hold someone accountable for the damage to our trains.
Benefits of working on the edge
Reduce the power consumption of the device
Reduce data transmission rate - conserve bandwidth
Improve privacy
Real-time reaction to events
Reduction of latency
Enable Smart Applications
Machine learning on the edge occurs more frequently, and pre-processing data on the edge will be a necessity the further we proceed in the Internet of Things universe. Making freight trains smarter is just one use case of many in which edge ML plays a significant role in reducing costs, increasing efficiency, and automating the system.